Dual-Stage 클러스터링으로 장애물 분리 정밀도 높이기
Dual-Stage 클러스터링으로 장애물 분리 정밀도 높이기
설계 목표
- 객체 분리 정밀도 향상: 거리와 입사각에 따른 가변 임계값을 적용하여 원거리 객체의 파편화(Fragmentation) 현상을 방지하고 탐지 안정성을 확보합니다.
- 기하학적 특징 모델링: 클러스터링된 데이터를 사각형 형태로 정형화하여 추적(Tracking)에 필요한 핵심 파라미터(위치, 크기, 방향)를 도출합니다.
개요
본 문서에서는 2D LiDAR 데이터를 활용하여 이동 차량을 정밀하게 탐지하기 위한 Segmentation 알고리즘의 발전 과정과 Feature Extraction 방법론을 기술합니다. 기초적인 거리 기반 방식에서 시작하여 실제 적용된 적응형 클러스터링까지의 단계별 개선 사항을 다룹니다.
Breakpoint Detector
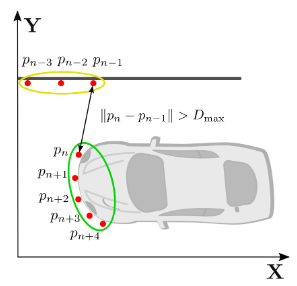
Breakpoint Detector(BP)는 n개의 점으로 구성된 2D LiDAR 포인트 클라우드에서 인접한 점 사이의 유클리드 거리를 기준으로 클러스터링을 수행하는 가장 기초적인 방식입니다.
- 연속된 두 점 $p_{n}$과 $p_{n-1}$ 사이의 거리가 사전에 정의된 고정 임계값 $D_{max}$보다 작을 경우 동일한 클러스터로 분류하고, 이를 초과할 경우 새로운 클러스터를 생성합니다.
- 고정된 임계값은 LiDAR 센서로부터 거리가 멀어짐에 따라 포인트 밀도가 낮아지는 특성을 반영하지 못합니다. 이로 인해 원거리 객체의 측정값이 서로 다른 클러스터로 분할되어 인식되는 파편화 문제가 발생합니다.
Adaptive Breakpoint Detector
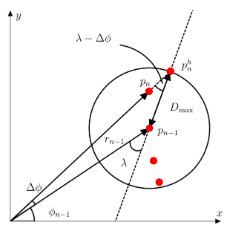
Adaptive Breakpoint Detector(ABP)는 BP의 한계를 해결하기 위해 측정 거리에 따라 임계값 $D_{max}$를 동적으로 조정하는 알고리즘입니다.
- 센서의 스캐닝 각도, 분해능, 그리고 물체에 대한 입사각($\lambda$)을 고려하여 이론적인 최대 거리 $r_{n}^{h}$를 산출합니다. 이를 통해 거리가 멀어질수록 임계값 또한 비례하여 커지도록 설계하였습니다.
- 센서 고유의 오차를 고려하여 기하학적 거리 계산 결과에 오차 분산 $\sigma_{r}$을 추가함으로써 근거리 데이터의 안정성을 확보하였습니다.
Adaptive Breakpoint Detector (Dual-Stage)
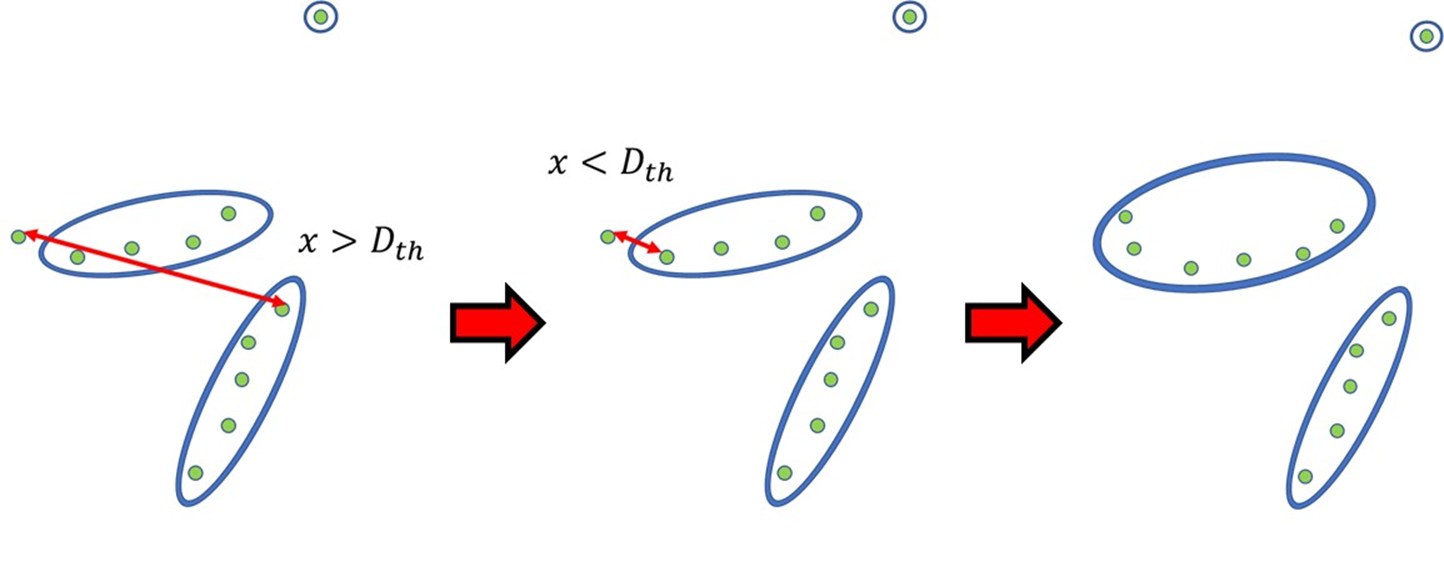
기존 ABP 알고리즘을 Dual-Stage Clustering 방식으로 확장하였습니다.
- 1st Stage (Point-to-Point): ABP 기반의 Point-to-Point 방식으로 연속된 점들을 클러스터링합니다.
- 2nd Stage (Point-to-Cluster): 1st Stage에서 임계값을 초과할 경우, 기존에 생성된 모든 클러스터와 대조합니다. 트랙 필터링 과정에서 벽면 등의 점이 제거되면 동일 객체의 연속된 점들 사이 거리가 멀어질 수 있는데, 이때 최단 거리 클러스터가 임계값 내에 있다면 해당 그룹에 병합하여 객체 분할 현상을 방지합니다.
- $3\sigma$ 노이즈 핸들링을 적용하여 LiDAR 측정 노이즈에 대한 데이터 신뢰도를 높였습니다.
- 모든 연산을 Global Map Frame에서 수행하여 차량의 급격한 거동 중에도 장애물 탐지의 연속성을 보장하였습니다.
Feature Extraction 및 산출 파라미터
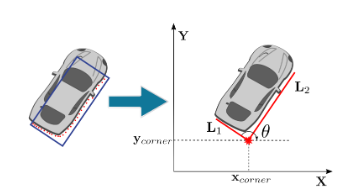
세분화된 클러스터로부터 구체적인 장애물의 형상을 정의하기 위해 Search-Based Rectangle Fitting 알고리즘을 수행합니다.
- 0도부터 89도까지의 모든 각도 후보군에 대해 성능 스코어를 계산하여 최적의 사각형 각도를 산출합니다.
- 피팅 과정을 통해 다음과 같은 핵심 특징값을 추출하며, 이는 추적(Tracking) 단계의 기초 데이터가 됩니다.
- 위치 ($x_{corner}, y_{corner}$): 센서와 가장 가까운 지점의 코너 좌표 또는 중심 좌표입니다.
- 크기 ($L_{1}, L_{2}$): 추출된 직사각형의 너비와 길이 정보입니다.
- 방향 각도 ($\theta$): 객체가 바라보고 있는 헤딩(Heading) 각도입니다.
파라미터 기반 장애물 식별 기준
추출된 파라미터를 기반으로 유효한 장애물을 최종 판정하기 위해 다음과 같은 임계값 필터를 적용합니다.
| 판단 기준 | 파라미터 명칭 | 임계값 (Threshold) | 역할 및 분석 |
|---|---|---|---|
| 데이터 밀도 | min_size_n_ | 10개 이상 | 포인트 수가 부족한 부유 노이즈 제거 |
| 물리적 크기 | min_size_m_ | 0.2 m 이상 | 소형 노이즈를 제외한 유의미한 차량 크기 필터링 |
| 물리적 크기 | max_size_m_ | 0.5 m 이하 | 비정상적으로 큰 물체 인지 배제 |
| 인식 범위 | max_viewing_distance_ | 9.0 m 이내 | 데이터 정밀도가 보장되는 유효 범위 제한 |
| 공간 제약 | GridFilter | Track Inside | 맵 정보를 대조하여 트랙 내부의 객체만 선별 |
마무리
본 알고리즘을 통해 추출된 정적 및 동적 장애물 데이터는 이후 Kalman Filter 기반의 추적 모듈과 연동되어 장애물의 경로 예측에 활용됩니다.
주요 포인트를 요약하면:
- Adaptive Breakpoint Detector: 거리에 따라 동적으로 임계값을 조정하여 원거리 객체의 파편화를 방지합니다
- Dual-Stage Clustering: Point-to-Point와 Point-to-Cluster 두 단계를 거쳐 더욱 정확한 클러스터링을 수행합니다
- Rectangle Fitting: Search-Based 알고리즘으로 장애물의 위치, 크기, 방향을 추출합니다
이 기법은 Grid Filter와 함께 사용하여 트랙 내부의 유효한 장애물만 선별하고, Tracking 모듈과 연동하여 장애물의 경로를 예측하는 데 활용됩니다.
This post is licensed under CC BY 4.0 by the author.